Our projects
Media Ingestion
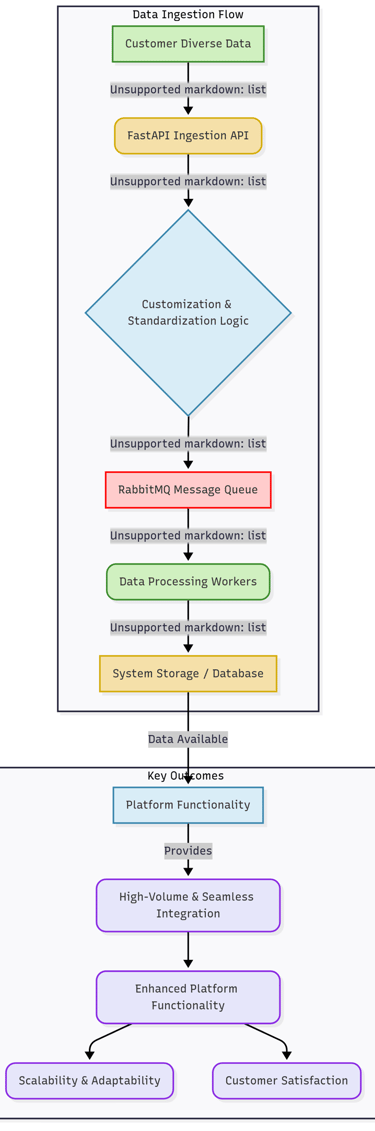
Spearheaded the development of a robust and scalable data ingestion and processing API using FastAPI. This project featured the implementation of RabbitMQ for efficient asynchronous task processing, ensuring seamless and high-volume data integration for new customers.
A key functionality built allows customers to directly ingest their diverse data into the system. This involved developing advanced customization and parsing mechanisms to standardize incoming data, significantly enhancing the platform's overall functionality, scalability, and adaptability to varied client requirements while boosting customer satisfaction.
Promotions Data Transformation Workflow
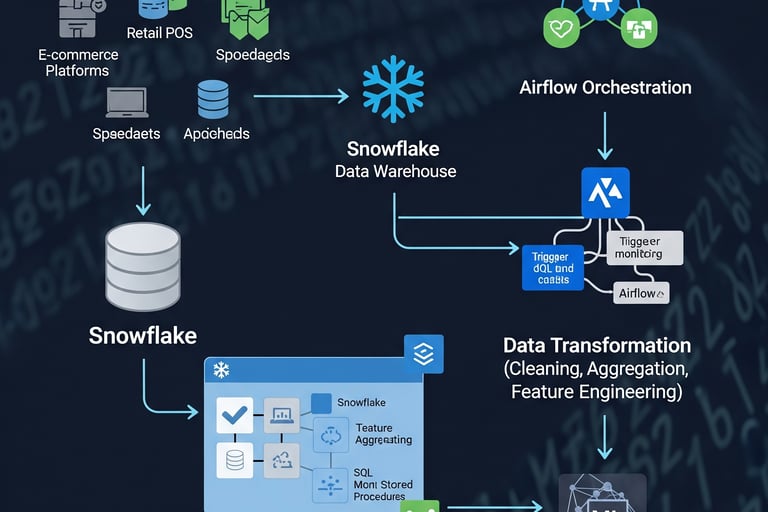
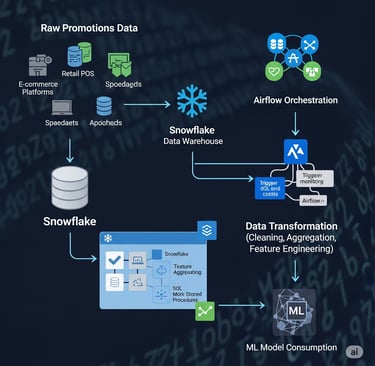
Designed and implemented a robust data transformation workflow, centralizing the processing of promotions data. This involved updating the Snowflake database with new customer data deliveries and integrating processing steps into a custom data pipeline.
Key responsibilities included developing complex table joining logic (Promotions, Common Promotions, Price Specification) and data transformation logic within stored SQL procedures to accurately calculate promotional prices and ranks. The workflow leveraged a Generic Plugin and API for execution on Snowflake, which was then orchestrated using Apache Airflow within the main data processing pipeline.
The initiative ensured transformed data was efficiently appended to the promotions transformation table, making it readily available for consumption by the ML model
Interactive ML Data Visualization Dashboard
Developed an interactive Streamlit dashboard for visualizing and analyzing ML model training data. This solution efficiently fetches and displays key metrics from MLflow runs (training/prediction/snapshot times, delta values) and generates progressive graphs for insightful trend analysis.
It connects to a PostgreSQL database for data retrieval based on specific criteria and presents insights via data-driven bar charts. Performance was significantly boosted through Redis caching to reduce loading times and multithreading for accelerated data retrieval across multiple customers.

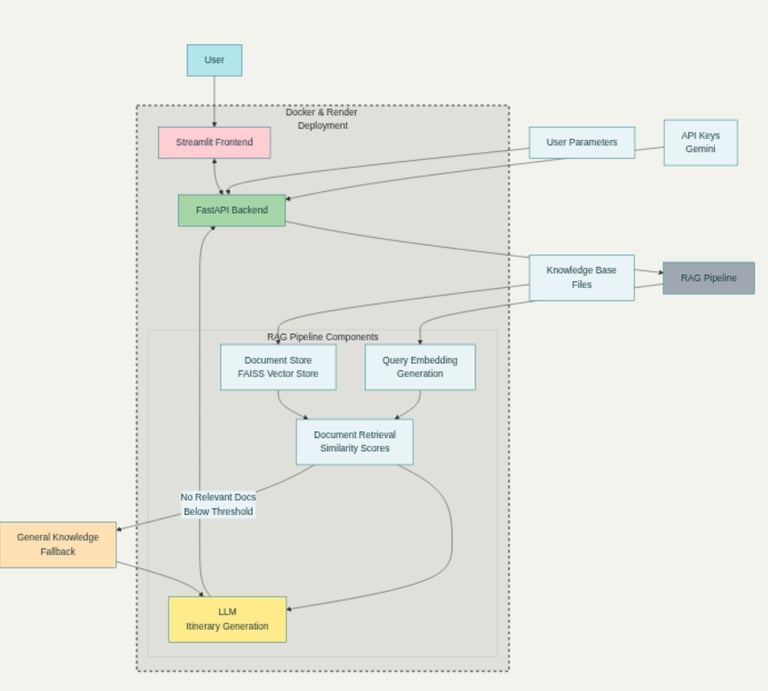
AI Trip Planner with RAG
Developed a full-stack, production-grade AI Trip Planner to generate personalized and factually-grounded travel itineraries.
Architected a robust system using a FastAPI backend and a Streamlit frontend, containerized with Docker. The core of the application features a Retrieval-Augmented Generation (RAG) pipeline that leverages a FAISS vector store to ground LLM responses in custom knowledge documents, with an intelligent fallback to general knowledge.
Engineered for reliability with defensive output sanitization and deployed to the cloud, demonstrating end-to-end AI application delivery.